CART (Classification And Regression Tree)
概述
求 \(R_m\):
扩张树:用贪心,上至下递归分区方法
split function 选择最好的特征 \(j*\) 和该特征最好的值 \(t*\)
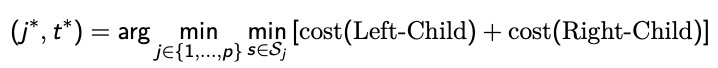
Split s divide the current node into two children.
比如,对于 t,\(\text{Left-Child }= {(y_i, x_i) : x_{ij} ≤ t}\ 而\ \text{Right-Child }= {(y_i, x_i) : x_{ij} > t}\)
2D 的例子
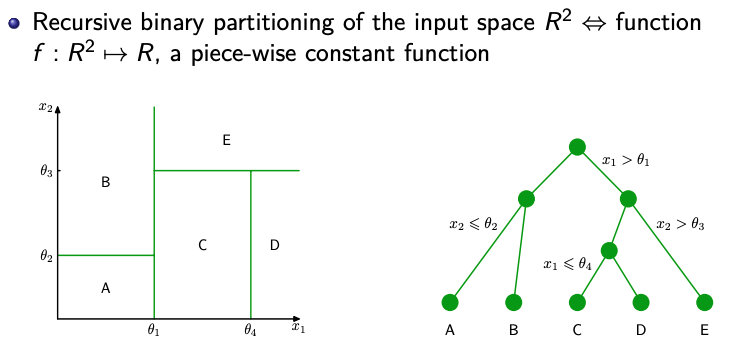
Splitting 规则
1. Regression

2. Classification

不纯度函数(impurity function)
当所有样本都属于同一类时候 \(I\) 取最小值. 即 \(I\) 在点 \((1,0,…,0),(0,1,…,0),…,(0,..,0,1)\) 取最小值.
当样本中每个类目下样本个数相同时I取最大值. 即 \(I\) 在点 \((1/k,..,1/k)\) 取最大值.
Prunning 剪枝
代价复杂性剪枝 (cost complexity pruning)
$$min \ \ \frac {1}{N} \sum^{\vert T \vert}_{m=1} \sum_{x_i \in {R_m}} L(y_i, w_m) + \alpha \vert T\vert$$
\(\vert T \vert\) 是 termainal nodes 的总数
\(L(·, ·)\) 是 loss function, 例如 \(L(yi, f (x_i)) = L(x_i,w_m) = (y_i − w_m)^2\)
\(w_m\) 是与 \(R_m\) 对应的预测值 \(\rightarrow\) 也就是 \(R_m\) 中训练集的平均值
算法



Multiple trees:
- bagging 袋装法
- random forests 随机森林
- boosting 提升法
boosting
基本思想:
在分类问题中,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类器的性能。
历史:
- PAC learning framework (1990)
- AdaBoost methods (1996)
- gradient boosting (2000)
weak learner:
classifiers whose error rate is slightly better than random guessing
Boosting 改变训练样本的权重,产生一系列的分类器: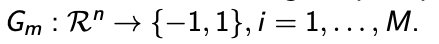
最终的分类器可以表示为: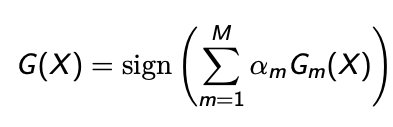
\(\alpha_m\):分类系数(由 boosting 算法计算得出)
AdaBoost



随机森林
你可能会问为什么不直接使用一个决策树?这种分类器堪称完美,因为根本不会犯任何错误!但要记住一个重点:决策树只是不会在训练数据上犯错。
随机森林是由许多决策树构成的模型。这不仅仅是森林,而且是随机的,这涉及到两个概念:
随机采样数据点
基于特征的子集分割节点
随机森林由LeoBreiman(2001)提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
随机森林的构建过程
决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。但是俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取。
数据的随机选取
首先,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。第二,利用子数据集来构建子决策树,将这个数据放到每个子决策树中,每个子决策树输出一个结果。最后,如果有了新的数据需要通过随机森林得到分类结果,就可以通过对子决策树的判断结果的投票,得到随机森林的输出结果了。
随机森林采用的是bagging的思想,bagging又称为bootstrap aggreagation,通过在训练样本集中进行有放回的采样得到多个采样集,基于每个采样集训练出一个基学习器,再将基学习器结合。随机森林在对决策树进行bagging的基础上,在决策树的训练过程中引入了随机属性选择。传统决策树在选择划分属性的时候是在当前节点属性集合中选择最优属性,而随机森林则是对结点先随机选择包含k个属性的子集,再选择最有属性,k作为一个参数控制了随机性的引入程度。
另外,GBDT训练是基于Boosting思想,每一迭代中根据错误更新样本权重,因此是串行生成的序列化方法,而随机森林是bagging的思想,因此是并行化方法。
尽管有剪枝等等方法,一棵树的生成肯定还是不如多棵树,因此就有了随机森林,解决决策树泛化能力弱的缺点。(可以理解成三个臭皮匠顶过诸葛亮)
而同一批数据,用同样的算法只能产生一棵树,这时Bagging策略可以帮助我们产生不同的数据集。Bagging策略来源于bootstrap aggregation:从样本集(假设样本集N个数据点)中重采样选出Nb个样本(有放回的采样,样本数据点个数仍然不变为N),在所有样本上,对这n个样本建立分类器(ID3\C4.5\CART\SVM\LOGISTIC),重复以上两步m次,获得m个分类器,最后根据这m个分类器的投票结果,决定数据属于哪一类。
随机森林在bagging的基础上更进一步:
样本的随机:从样本集中用Bootstrap随机选取n个样本
特征的随机:从所有属性中随机选取K个属性,选择最佳分割属性作为节点建立CART决策树(泛化的理解,这里面也可以是其他类型的分类器,比如SVM、Logistics)
重复以上两步m次,即建立了m棵CART决策树
这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类(投票机制有一票否决制、少数服从多数、加权多数)
假设随机森林中有3棵子决策树,2棵子树的分类结果是A类,1棵子树的分类结果是B类,那么随机森林的分类结果就是A类。
关于调参:
- 如何选取K,可以考虑有N个属性,取K=根号N
- 最大深度(不超过8层)
- 棵数
- 最小分裂样本树
- 类别比例