强化学习(二)
强化学习(RL,基于MDP)的求解policy的方式一般分为三种:
- Value <—critic
- Policy <—actor
- Value + Policy <— Actor-critic
策略梯度
强化学习是一个通过奖惩来学习正确行为的机制. 家族中有很多种不一样的成员, 有学习奖惩值, 根据自己认为的高价值选行为, 比如 Q learning, Deep Q Network, 也有不通过分析奖励值, 直接输出行为的方法, 这就是今天要说的 Policy Gradients 了. 甚至我们可以为 Policy Gradients 加上一个神经网络来输出预测的动作. 对比起以值为基础的方法, Policy Gradients 直接输出动作的最大好处就是, 它能在一个连续区间内挑选动作, 而基于值的, 比如 Q-learning, 它如果在无穷多的动作中计算价值, 从而选择行为, 这, 它可吃不消.
有了神经网络当然方便, 但是, 我们怎么进行神经网络的误差反向传递呢? Policy Gradients 的误差又是什么呢? 答案是! 哈哈, 没有误差! 但是他的确是在进行某一种的反向传递. 这种反向传递的目的是让这次被选中的行为更有可能在下次发生. 但是我们要怎么确定这个行为是不是应当被增加被选的概率呢? 这时候我们的老朋友, reward 奖惩正可以在这时候派上用场,
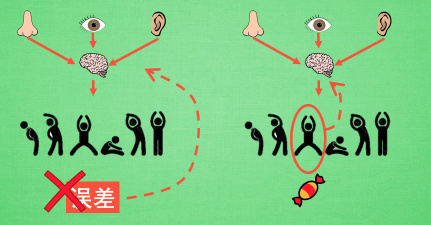
现在我们来演示一遍, 观测的信息通过神经网络分析, 选出了左边的行为, 我们直接进行反向传递, 使之下次被选的可能性增加, 但是奖惩信息却告诉我们, 这次的行为是不好的, 那我们的动作可能性增加的幅度 随之被减低. 这样就能靠奖励来左右我们的神经网络反向传递. 我们再来举个例子, 假如这次的观测信息让神经网络选择了右边的行为, 右边的行为随之想要进行反向传递, 使右边的行为下次被多选一点, 这时, 奖惩信息也来了, 告诉我们这是好行为, 那我们就在这次反向传递的时候加大力度, 让它下次被多选的幅度更猛烈! 这就是 Policy Gradients 的核心思想了. 很简单吧.
Policy gradient 是 RL 中另外一个大家族, 他不像 Value-based 方法 (Q learning, Sarsa), 但他也要接受环境信息 (observation), 不同的是他要输出不是 action 的 value, 而是具体的那一个 action, 这样 policy gradient 就跳过了 value 这个阶段. 而且个人认为 Policy gradient 最大的一个优势是: 输出的这个 action 可以是一个连续的值, 之前我们说到的 value-based 方法输出的都是不连续的值, 然后再选择值最大的 action. 而 policy gradient 可以在一个连续分布上选取 action.
介绍的 policy gradient 的第一个算法是一种基于 整条回合数据 的更新, 也叫 REINFORCE 方法. 这种方法是 policy gradient 的最基本方法, 有了这个的基础, 我们再来做更高级的.
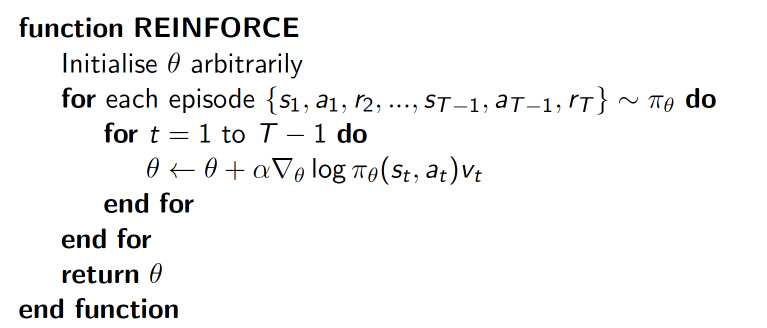
log(Policy(s,a))*V 中的 log(Policy(s,a)) 表示在 状态 s 对所选动作 a 的吃惊度, 如果 Policy(s,a) 概率越小, 反向的 log(Policy(s,a)) (即 -log(P)) 反而越大. 如果在 Policy(s,a) 很小的情况下, 拿到了一个 大的 R, 也就是 大的 V, 那 -log(Policy(s, a))*V 就更大, 表示更吃惊, (我选了一个不常选的动作, 却发现原来它能得到了一个好的 reward, 那我就得对我这次的参数进行一个大幅修改). 这就是 log(Policy)*V 的物理意义啦
策略梯度
Actor Critic
我们有了像 Q-learning 这么伟大的算法, 为什么还要瞎折腾出一个 Actor-Critic? 原来 Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率.
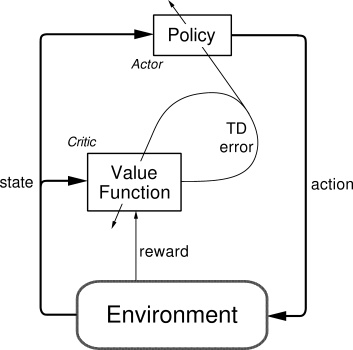
或者说详细点, 就是 Actor 在运用 Policy Gradient 的方法进行 Gradient ascent 的时候, 由 Critic 来告诉他, 这次的 Gradient ascent 是不是一次正确的 ascent, 如果这次的得分不好, 那么就不要 ascent 那么多.
DDPG
