Perceptual Loss 感知损失 图像超分辨重建(二)
1 概述
文章:Perceptual Losses for Real-Time Style-Transfer and Super-Resolution
作者: Justin Johnson, Alexandre Alahi, Li Fei-Fei
相较于其他机器学习任务,如物体检测(object detection)或者实例分割(instance segmentation),超分辨重建技术中学习任务的损失函数的定义通常都相对简单粗暴,由于我们重建的目的是为了使得重建的高分辨率图片与真实高清图片之间的峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)尽可能的大,因此绝大多数的基于深度学习的超分辨重建研究都直接的将损失函数设计为平均均方差(Mean Square Error, MSE),即计算两幅图片所有对应像素位置点之间的均方差,由于MSE Loss要求像素点之间位置一一对应,因此又被称作Per-Pixel Loss。
但随着技术的发展,研究者慢慢发现Per-Pixel Loss的局限性。考虑一个极端的情况,将高清原图向任意方向偏移一个像素,事实上图片本身的分辨率与风格并未发生太大的改变,但Per-Pixel Loss却会因为这一个像素的偏移而出现显著的上升,因此Per-Pixel Loss的约束并不能反应图像高级的特征信息(high-level features)。
图像风格转换算法的成功,在生成图像领域,产生了一个非常重要的idea,那就是可以将卷积神经网络提取出的feature,作为目标函数的一部分,通过比较待生成的图片经过CNN的feature值与目标图片经过CNN的feature值,使得待生成的图片与目标图片在语义上更加相似(相对于Pixel级别的损失函数)。
图像风格转换算法将图片生成以生成的方式进行处理,如风格转换,是从一张噪音图(相当于白板)中得到一张结果图,具有图片A的内容和图片B的风格。而Perceptual Losses则是将生成问题看做是变换问题。即生成图像是从内容图中变化得到。
图像风格转换是针对待生成的图像进行求导,CNN的反向传播由于参数众多,是非常慢的,同样利用卷积神经网络的feature产生的loss,训练了一个神经网络,将内容图片输入进去,可以直接输出转换风格后的图像。而将低分辨率的图像输入进去,可以得到高分辨率的图像。因为只进行一次网络的前向计算,速度非常快,可以达到实时的效果。
研究图像风格迁移的研究者们相对于Per-Pixel Loss在2016年的CVPR会议上提出了Perceptual Loss的概念。
2 构架
下面这个网络图是论文的精华所在。图中将网络分为Transform网络和Loss网络两种,在使用中,Transform网络用来对图像进行转换,它的参数是变化的,而Loss网络,则保持参数不变,Transform的结果图,风格图和内容图都通过Loss Net得到每一层的feature激活值,并以之进行Loss计算。
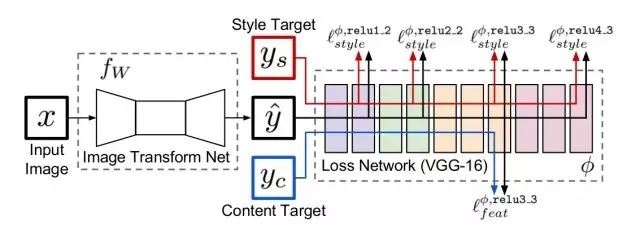
在风格转换上,输入 \(x=y_c\) 是内容图片。而在图片高清化上, \(x\) 是低分辨率图片,内容图片是高分辨率图片,风格图片未曾使用。
3 网络细节
网络细节的设计大体遵循DCGAN中的设计思路:
- 不使用pooling层,而是使用strided和fractionally strided卷积来做downsampling和upsampling,
- 使用了五个residual blocks
- 除了输出层之外的所有的非residual blocks后面都跟着spatial batch normalization和ReLU的非线性激活函数。
- 输出层使用一个scaled tanh来保证输出值在 \([0, 255]\) 内。
- 第一个和最后一个卷积层使用9×9的核,其他卷积层使用 \(3\times 3\) 的核。
4 损失函数
同图像风格转换(Image style transfer)算法类似,论文定义了两种损失函数。其中,损失网络都使用在ImageNet上训练好的VGG net,使用 \(φ\) 来表示损失网络。
损失函数由三部分组成
4.1 Feature Reconstruction Loss
$$l^{\phi,j}_{feat}(\hat{y},y)={\frac {1}{C_jH_jW_j}}{\Vert {\phi_{j}(\hat{y})-\phi_{j}({y})} \Vert}^{2}_{2}$$
- \(j\) 表示网络的第 \(j\) 层
- \(C_jH_jW_j\) 表示第 \(j\) 层的 feature_map 的 size
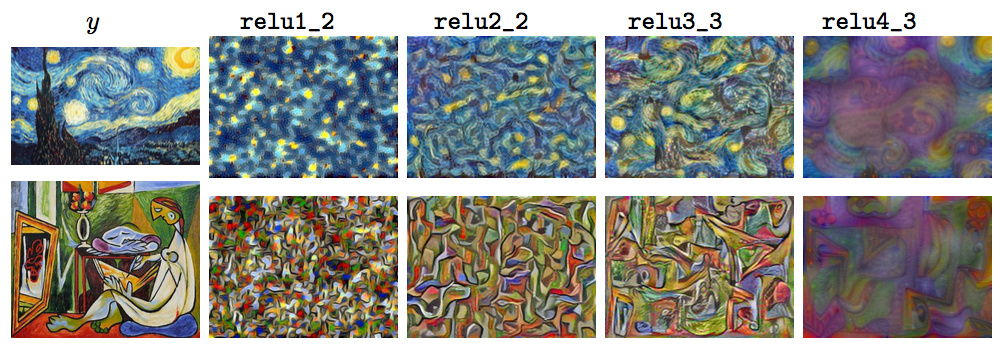
使用不同层的重建效果如下:

4.2 Style Reconstruction Loss
对于风格重建的损失函数,首先要先计算Gram矩阵,
$$G^{\phi}_{j}(x)_{c,c′}={\frac {1}{C_jH_jW_j}}{\sum^{H_{j}}_{h=1}}{\sum^{W_{j}}_{w=1}}{\phi}_{j}(x)_{h,w,c}{\phi}_{j}(x)_{h,w,c′}$$
产生的 feature_map 的大小为 \(C_jH_jW_j\),可以看成是 \(C_j\) 个特征,这些特征两两之间的内积的计算方式如上。
$$l^{\phi,j}_{style}(\hat{y},y)=\Vert {G_{j}^{\phi}(\hat{y})-G_{j}^{\phi}({y})} \Vert^{2}_{F}$$
两张图片,在loss网络的每一层都求出Gram矩阵,然后对应层之间计算欧式距离,最后将不同层的欧氏距离相加,得到最后的风格损失。
不同层的风格重建效果如下:
4.3 Simple Loss Function
第三个部分不是必须的
1) Pixel Loss
pixel loss 是输出 \(\hat y\) 和目标 \(y\) 之间的欧几里得距离,只在网络有需要匹配的 ground-truth target \(y\) 时才使用
$$l_{pixel}(\hat{y}, y)=\Vert {\hat{y}}-y \Vert^{2}_{2}$$
2)Total Variation Regularization
Total Variation Loss,实际上是一个平滑项(一个正则化项),目的是使生成的图像在局部上尽可能平滑,而它的定义和马尔科夫随机场(MRF)中使用的平滑项非常相似。
$$l_{TV}(\hat y)={\sum}_{n}{\Vert \hat{y}_{n+1}- \hat{y}_{n} \Vert}^{2}_{2}$$
- 其中 \(y_{n+1}\) 是 \(y_n\) 的相邻像素
5 基于Per-Pixel Loss的超分辨重建网络
基于Per-Pixel Loss的超分辨重建网络目标在于直接最小化高清原图与超分辨重建图像之间的差异,使得超分辨重建图像逐步逼近原图的清晰效果。但Perceptual Loss最小化的是原图与重建图像的特征图之间的差异,为了提高计算效率,Perceptual Loss中的特征图由固定权重值的卷积神经网络提取,例如在ImageNet数据集上预训练得到的VGG16网络,如下图所示,不同深度的卷积层提取的特征信息不同,反映的图像的纹理也不同。

因此研究者们在训练超分辨神经网络时,利用跨间隔的卷积层(strided convolution layer)代替池化层(pooling layer)构建全卷积神经网络(Fully Convolutional Network, FCN)进行超分辨重建,并在卷积层之间添加残差结构(residual block)以在保证网络拟合性能的前提下加深网络深度获得更佳表现。最终利用VGG16网络对原图与重建图像进行特征提取,最小化两者特征图之间的差异使得超分辨重建图像不断逼近原图的分辨率。