SRCNN 图像超分辨重建(一)
1 概述
分辨率极限,无论对于图像重建或是图像后处理算法的研究者,都是一项无法回避的技术指标。
- 时间分辨率性能决定了视频输出的帧率,即实时效果;
- 空间分辨率性能决定了图像的画面清晰度究竟是720P,1080P,还是4K;
- 色阶分辨率性能决定了图像显示色彩的丰满程度与粒度。
因此,分辨率是一幅图像、一段视频的核心。
应用场景举例:
图片压缩与传输,即以较低的码率进行图像编码,在传输过程中可极大节省转发服务器的流量带宽,在客户端解码得到相对低清晰度的图片,最后通过超分辨重建技术处理获得高清晰度图片
传统超分辨重建技术大体上可分为4类:
- 预测型(prediction-based)
- 边缘型(edge-based)
- 统计型(statistical)
- 图像块型(patch-based/example-based)
目前大家使用最多的是图像块型
SR 也可分为两类:
- 从多张低分辨率图像重建出高分辨率图像
- 从单张低分辨率图像重建出高分辨率图像
基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)。
SISR是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。
在传统的方法中,这个先验信息可以通过若干成对出现的低-高分辨率图像的实例中学到。而基于深度学习的SR通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
我们在图像块型领域选择了4篇基于深度学习的图像块型超分辨重建的经典论文进行关键技术点分析。
从论文中我们可以看出研究者们对于超分辨任务的不同的理解与解决问题思路。
2 SRCNN
Super-Resolution Convolutional Neural Network
SRCNN, PAMI 2016, http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
SRCNN是基于深度学习的超分辨重建领域的开山之作,继承了传统机器学习领域稀疏编码的思想,该方法对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。
2.1 结构
利用三层卷积层分别实现:
- 图像的图像块抽取与稀疏字典建立
- 图像高、低分辨率特征之间的非线性映射
- 高分辨率图像块的重建
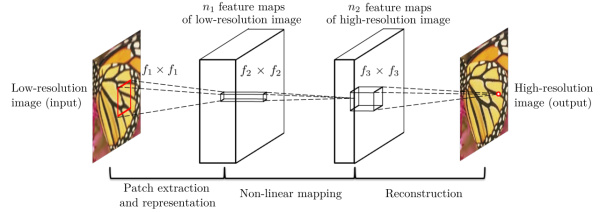
SRCNN的流程为:
先将低分辨率图像使用双三次差值放大至目标尺寸(如放大至2倍、3倍、4倍),此时仍然称放大至目标尺寸后的图像为低分辨率图像(Low-resolution image),即图中的输入(input);
将低分辨率图像输入三层卷积神经网络,
举例:在论文中的其中一实验相关设置,对YCrCb颜色空间中的Y通道进行重建,网络形式为
(conv1+relu1) \(\to\) (conv2+relu2) \(\to\) (conv3+relu3)
三个卷积层使用的卷积核的大小分为为 \(9\times 9\) , \(1\times 1\) 和 \(5\times 5\) ,前两个的输出特征个数分别为 \(64\) 和 \(32\)。
第一层卷积:卷积核尺寸 \(9×9\ (f_1×f_1)\) ,卷积核数目 \(64\ (n_1)\) ,输出64张特征图;
第二层卷积:卷积核尺寸 \(1×1\ (f_2×f_2)\) ,卷积核数目 \(32\ (n_2)\) ,输出32张特征图;
第三层卷积:卷积核尺寸 \(5×5\ (f_3×f_3)\) ,卷积核数目 \(1\ (n_3)\) ,输出1张特征图即为最终重建高分辨率图像。
具体地,假设需要处理的低分辨率图片的尺寸为 \(H \times W \times C\) , 其中 \(H、W、C\) 分别表示图片的长、宽和通道数;SRCNN第一层卷积核尺寸为 \(C \times f_1 \times f_1 \times n_1\) ,可以理解为在低分辨率图片上滑窗式地提取 \(f_1 \times f_1\) 的图像块区域进行n1种类型的卷积操作。在全图范围内,每一种类型卷积操作都可以输出一个特征向量,最终 \(n_1\) 个特征向量构成了低分辨率图片的稀疏表示的字典,字典的维度为 \(H_1 \times W_1 \times n_1\) ;
SRCNN第二层卷积核尺寸为 \(n_1 \times 1 \times 1 \times n_2\) ,以建立由低分辨率到高分辨率稀疏表示字典之间的非线性映射,输出的高分辨率稀疏字典的维度为 \(H_1 \times W_1 \times n_2\) ,值得注意的是在这一步中SRCNN并未采用全连接层(fully connected layer)来进行特征图或是稀疏字典之间的映射,而是采用1x1卷积核,从而使得空间上每一个像素点位置的映射都共享参数,即每一个空间位置以相同的方式进行非线性映射;
SRCNN第三层卷积核尺寸为 \(n_2 \times f_3 \times f_3 \times C\) ,由高分辨率稀疏字典中每一个像素点位置的 \(n_2 \times 1\) 向量重建 \(f_3 \times f_3\) 图像块,图像块之间相互重合覆盖,最终实现图片的超分辨率重建。
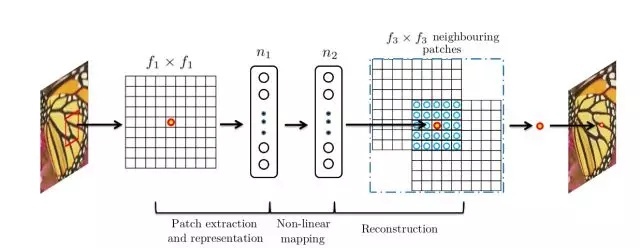
训练过程:
训练数据集:论文中某一实验采用91张自然图像作为训练数据集,对训练集中的图像先使用双三次差值缩小到低分辨率尺寸,再将其放大到目标放大尺寸,最后切割成诸多33×33图像块作为训练数据,作为标签数据的则为图像中心的21×21图像块(与卷积层细节设置相关);
注:最原始的SRCNN输入不是低分辨率图像,而是低分辨率双立方插值后的图片
损失函数:采用MSE函数作为卷积神经网络损失函数;
卷积层细节设置:第一层卷积核 \(9×9\) ,得到特征图尺寸为 \((33-9)/1+1=25\) ,第二层卷积核 \(1×1\) ,得到特征图尺寸不变,第三层卷积核 \(5×5\) ,得到特征图尺寸为 \((25-5)/1+1=21\) 。训练时得到的尺寸为 \(21×21\) ,因此图像中心的 \(21×21\) 图像块作为标签数据。(卷积训练时不进行padding)
2.2 重建效果
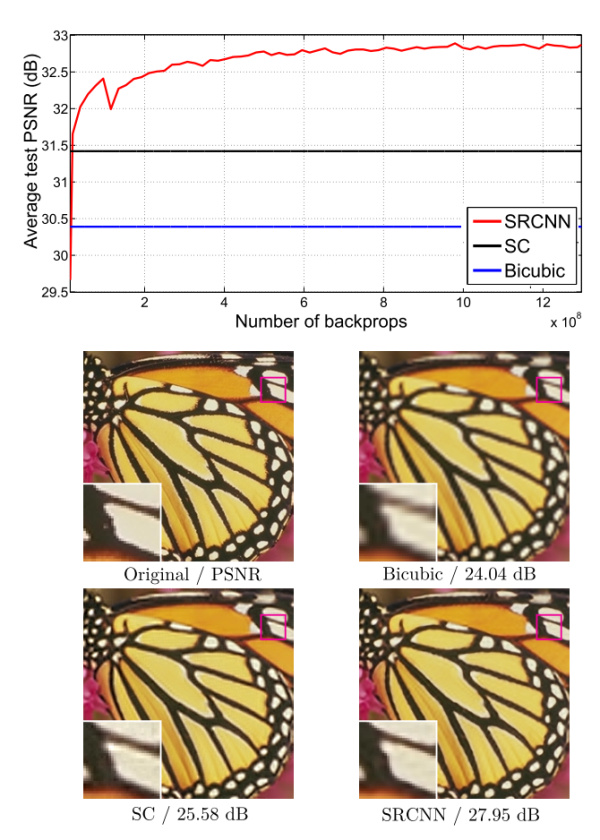
对SR的质量进行定量评价常用的两个指标是 PSNR(Peak Signal-to-Noise Ratio 峰值信噪比) 和 SSIM(Structure Similarity Index 结构相似性)。这两个值越高代表重建结果的像素值和金标准越接近,下图表明,在不同的放大倍数下,SRCNN都取得比传统方法好的效果。

该文章分别用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。相比于双三次插值和传统的稀疏编码方法,SRCNN得到的高分辨率图像更加清晰,下图是一个放大倍数为3的例子。
实践: