前言
最近看到一些利用python制作词云的教程,突然想到用自己和女友的聊天记录做一个词云,看看平时我俩最常说的都是啥,然后用爱心的形状展示出来,以下是成品:
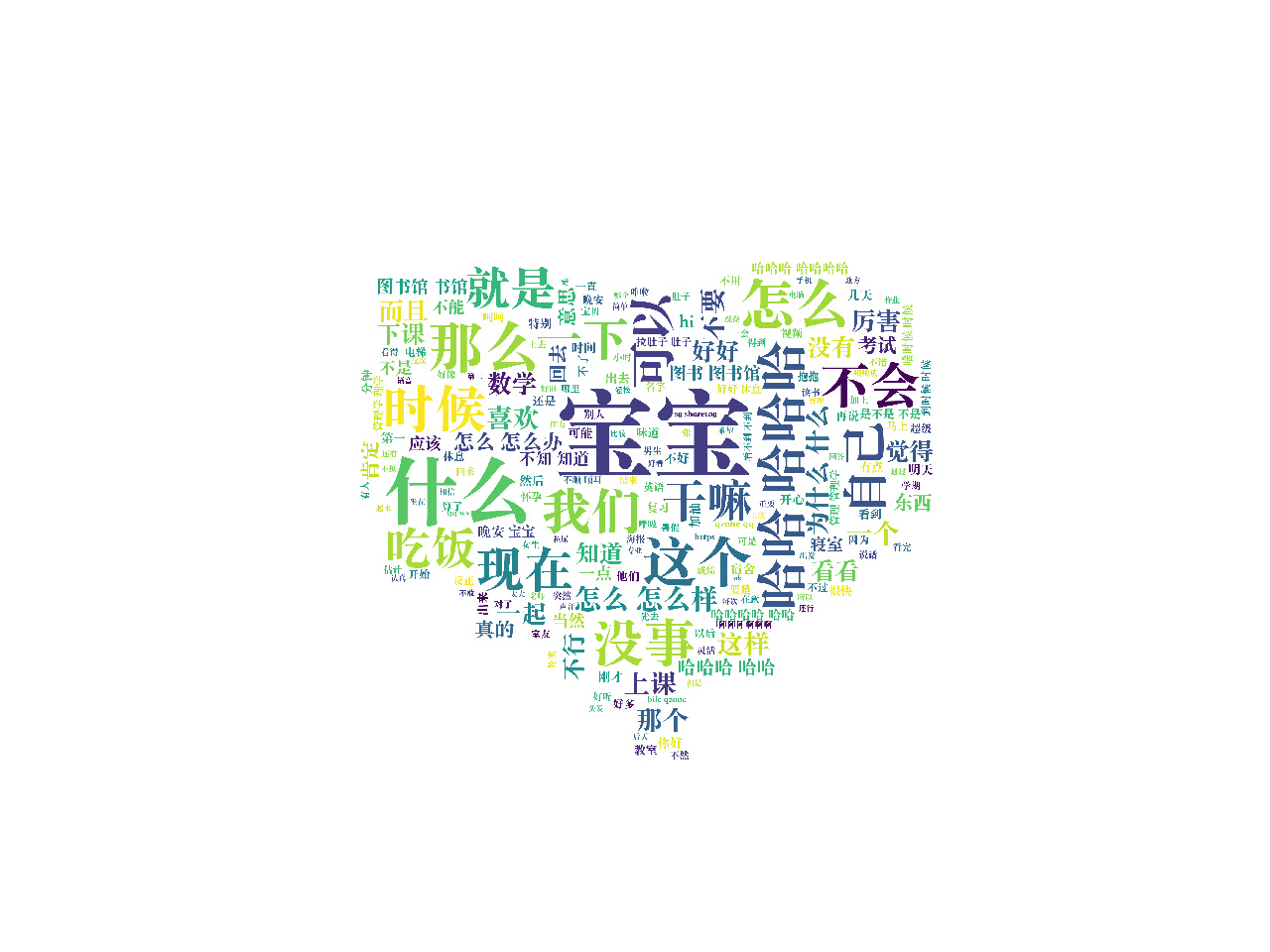
由于导出的记录只有最近两个星期的,再加上这两个星期我女票她都在备考,因此聊天内容并不是特别多,数据可能不是特别有代表性,但至少也能看看了。
数据处理
首先我们从QQ中导出txt格式的聊天记录,并在python中打开
1
2
| f = open('/Users/aaron/文档/My one and only.txt')
fl = f.readlines()
|
我们来查看一下数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| ['\ufeff消息记录(此消息记录为文本格式,不支持重新导入)\n',
'\n',
'================================================================\n',
'消息分组:My one and only\n',
'================================================================\n',
'消息对象:xxx\n',
'================================================================\n',
'\n',
'2018-01-12 下午4:00:40 xxx\n',
'好丑操\n',
'\n',
'2018-01-12 下午4:00:49 xxx\n',
'好臭\n',
'\n',
'2018-01-12 下午4:00:50 xxx\n',
'好臭\n',
'\n',
'2018-01-12 下午4:01:27 xxx\n',
'我吃牛肉干\n',
'\n',
|
可以看出前7行是头信息,下边的数据按照:
时间,
单句聊天记录,
‘\n’
每三行为一组,于是我们首先删去头信息
del fl[:8]
接下来我们只需要从下标为1开始,步长为3的聊天记录的数据:
fl = fl[1::3]
其中 [1::3] 的意思为下标为1开始,步长为3的切片,比如:
1
2
3
4
5
6
7
| >>> a = [0,1,2,3,4,5,6,7,8,9]
>>> a[1::3]
[1, 4, 7]
>>> a[::3]
[0, 3, 6, 9]
>>> a[:5:2]
[0, 2, 4]
|
之后的数据变为一个全部由聊天记录组成的列表:
1
2
3
4
5
6
7
8
| ['好丑操\n',
'好臭\n',
'好臭\n',
'我吃牛肉干\n',
'去去味\n',
'。。。。\n',
...
]
|
我们将其组成一个字符串,使用 ' '.join(list) 可以将一个列表组合成一个以空格为间隔的字符串:
strf = ' '.join(fl)
观察数据,发现记录中有非常多的杂质,例如 /扯一扯,/糊脸, [放大招], [表情] 等,我们需要将这些杂质都去掉,于是导入re正则表达式模块:
两种杂质,一种是以 / 开头,一种是 [xx] 形式,我们用两种正则表达式找出并转换为集合去掉重复元素
1
2
3
4
| list1 = re.findall(r'/.{2,3}', strf)
list2 = re.findall(r'\[.+?\]', strf)
set1 = set(list1)
set2 = set(list2)
|
我们可以看到:

以及
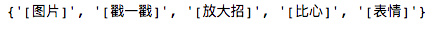
然后去掉这些杂质,因为有些出现频率太高会影响最后结果
1
2
3
4
| for item in set1:
strf = strf.replace(item, '')
for item in set2:
strf = strf.replace(item, '')
|
还有要自己手动去掉两条:
1
2
| strf = strf.replace('请使用最新版本手机QQ查看', '')
strf = strf.replace('请使用最新版手机QQ体验新功能', '')
|
数据干净之后就可以制作词云了。
jieba库
我们利用 jieba 库对记录进行分词操作,能将一个句子分为单个词语。我们对jieba做一个简单的了解,以下为官方文档中的一部分:
jieba.cut 方法接受三个输入参数: 需要分词的字符串;cut_all 参数用来控制是否采用全模式;HMM 参数用来控制是否使用 HMM 模型
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import jieba
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print("Full Mode: " + "/ ".join(seg_list))
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print("Default Mode: " + "/ ".join(seg_list))
seg_list = jieba.cut("他来到了网易杭研大厦")
print(", ".join(seg_list))
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造")
print(", ".join(seg_list))
|
输出:
1
2
3
4
5
6
7
| 【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
|
若相对jieba进行更深的了解,可以 点击此处
wordcloud库
我们使用wordcloud包生成词云图,首先了解一下其用法:
1
| class wordcloud.WordCloud(font_path=None, width=400, height=200, margin=2, ranks_only=None, prefer_horizontal=0.9,mask=None, scale=1, color_func=None, max_words=200, min_font_size=4, stopwords=None, random_state=None,background_color='black', max_font_size=None, font_step=1, mode='RGB', relative_scaling=0.5, regexp=None, collocations=True,colormap=None, normalize_plurals=True)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| font_path : string
width : int (default=400)
height : int (default=200)
prefer_horizontal : float (default=0.90)
mask : nd-array or None (default=None)
scale : float (default=1)
min_font_size : int (default=4)
font_step : int (default=1)
max_words : number (default=200)
stopwords : set of strings or None
background_color : color value (default=”black”)
max_font_size : int or None (default=None)
mode : string (default=”RGB”)
relative_scaling : float (default=.5)
color_func : callable, default=None
regexp : string or None (optional)
collocations : bool, default=True
colormap : string or matplotlib colormap, default=”viridis”
fit_words(frequencies)
generate(text)
generate_from_frequencies(frequencies[, ...])
generate_from_text(text)
process_text(text)
recolor([random_state, color_func, colormap])
to_array()
to_file(filename)
|
了解了这两个包之后,我们开始正式制作词云。
制作词云图
首先导入所需要的库:
1
2
3
| import matplotlib.pyplot as plt
import jieba
import wordcloud
|
然后利用词云进行分词操作,并将生成的列表合并成字符串:
1
2
| word_list = jieba.cut(strf, cut_all=True)
word = ' '.join(word_list)
|
之后利用wordcloud包,注意一定要加上中文字体的路径,因为wordcloud默认是英文字体,并不支持中文,我们只需自己指定字体即可,我这里使用的是宋体,并且指定背景颜色是白色。
1
| wc = wordcloud.WordCloud(font_path='/Library/Fonts/Songti.ttc', background_color='white').generate(word)
|
最后使用matplotlib进行绘制:
1
2
3
| plt.imshow(wc)
plt.axis('off')
plt.show()
|
词云图就生成好了:

心形词云
为了生成心形的词云,我们首先找一张心形的图片:

然后:
1
| from scipy.misc import imread
|
加上mask参数后再次制作词云:
1
2
3
4
5
6
| pic = imread('/Users/aaron/Pictures/aixin.png')
wc = wordcloud.WordCloud(mask=pic, font_path='/Library/Fonts/Songti.ttc', width=1000, height=500, background_color='white').generate(word)
plt.imshow(wc)
plt.axis('off')
plt.show()
|
心形词云图诞生!
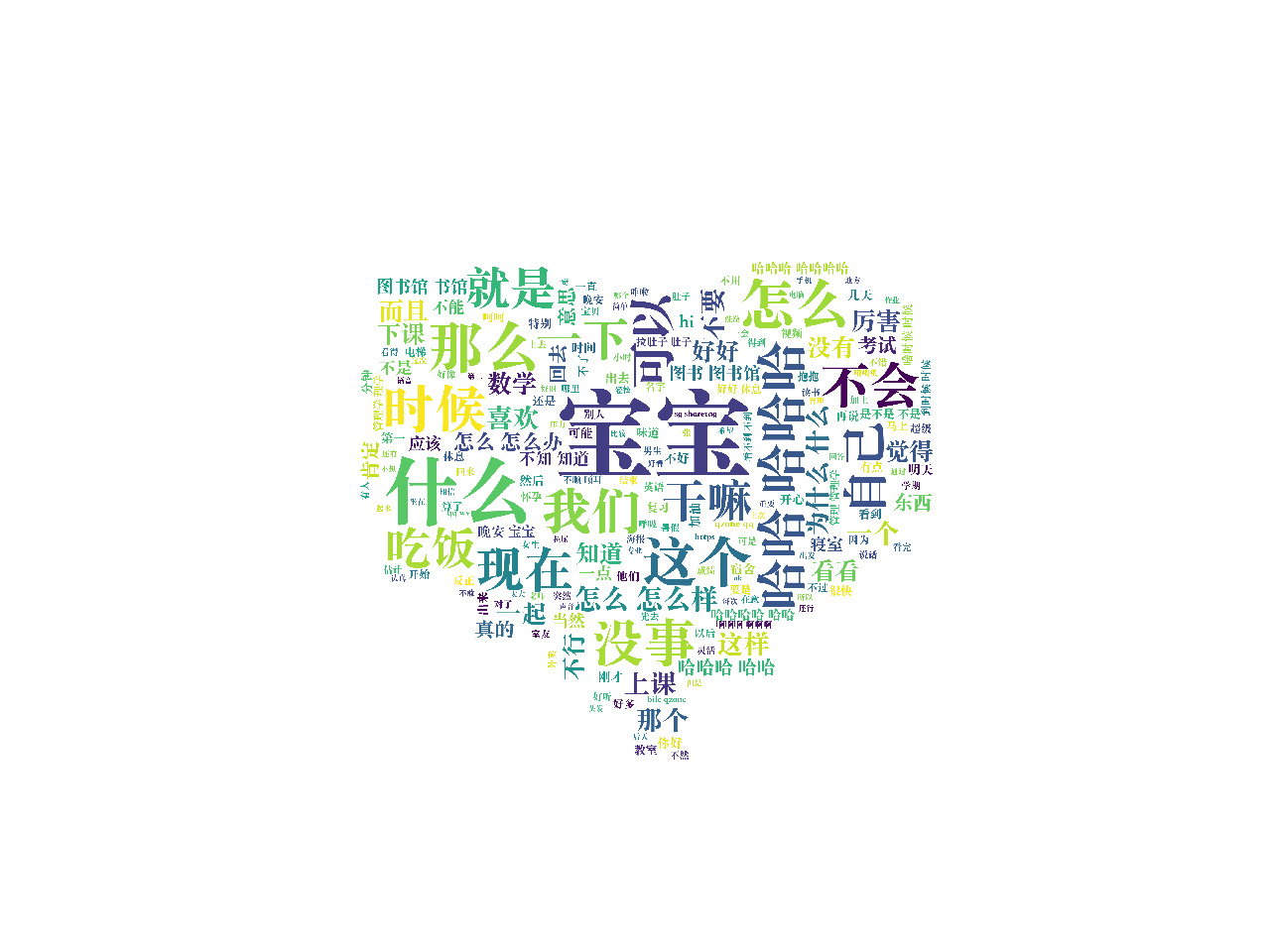
赶紧学一招然后发给自己的女朋友吧!
或许不是最优方法,欢迎指导。
代码
最后附上全部代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import re
import matplotlib.pyplot as plt
import jieba
import wordcloud
from scipy.misc import imread
f = open('/Users/aaron/文档/My one and only.txt')
fl = f.readlines()
del fl[:8]
fl = fl[1::3]
strf = ' '.join(fl)
list1 = re.findall(r'/.{2,3}', strf)
list2 = re.findall(r'\[.+?\]', strf)
set1 = set(list1)
set2 = set(list2)
strf = strf.replace('请使用最新版本手机QQ查看', '')
strf = strf.replace('请使用最新版手机QQ体验新功能', '')
for item in set1:
strf = strf.replace(item, '')
for item in set2:
strf = strf.replace(item, '')
word_list = jieba.cut(strf, cut_all=True)
word = ' '.join(word_list)
pic = imread('/Users/aaron/Downloads/aixin.png')
wc = wordcloud.WordCloud(mask=pic, font_path='/Library/Fonts/Songti.ttc', width=1000, height=500, background_color='white').generate(word)
plt.imshow(wc)
plt.axis('off')
plt.show()
|